林夕-博客
网站首页
文章专栏
资源分享
点点滴滴
关于本站
偷偷告诉大家,本博客的后台管理也正在制作,为大家准备了游客专用账号!
网站新增留言回复啦!使用QQ登陆即可回复,人人都可以回复!
如果你觉得网站做得还不错,来Fly社区点个赞吧!
点我前往
美文网 一个PHP&Golang程序员的个人博客,采用TP框架搭建,目前已完工!
点我前往
博客园 一个PHP&Golang程序员的个人博客,采用Yii2框架搭建,目前已完工!
点我前往
图书商城 一个PHP&Golang程序员的个人博客,前端采用weiui框架、后端采用Laravel5.5框架搭建,目前已完工!
点我前往
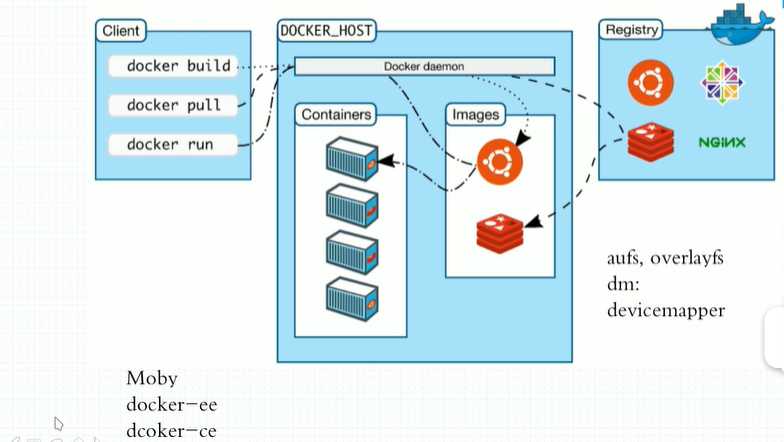
Docker存储驱动之--overlay2
docker支持多种graphDriver,包括vfs、devicemapper、overlay、overlay2、aufs......
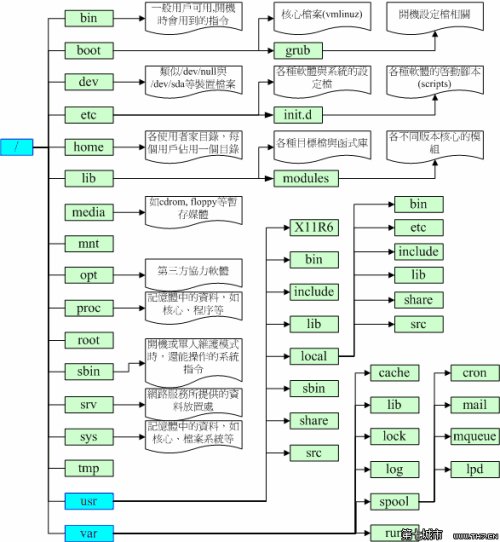
通过 proc 文件系统来访问 Linux 内核
最初开发 /proc 文件系统是为了提供有关系统中进程的信息。但是由于这个文件系统非常有用。因此,内核中的很多元素也开始使用它来报告信息,或启用动态运行时配置。
一个nvidia-docker引发k8s崩溃的问题探讨
nvidia-docker出现问题,我们该怎么去定位呢?定位后,怎么去解决呢?又能在此过程中学到什么呢?
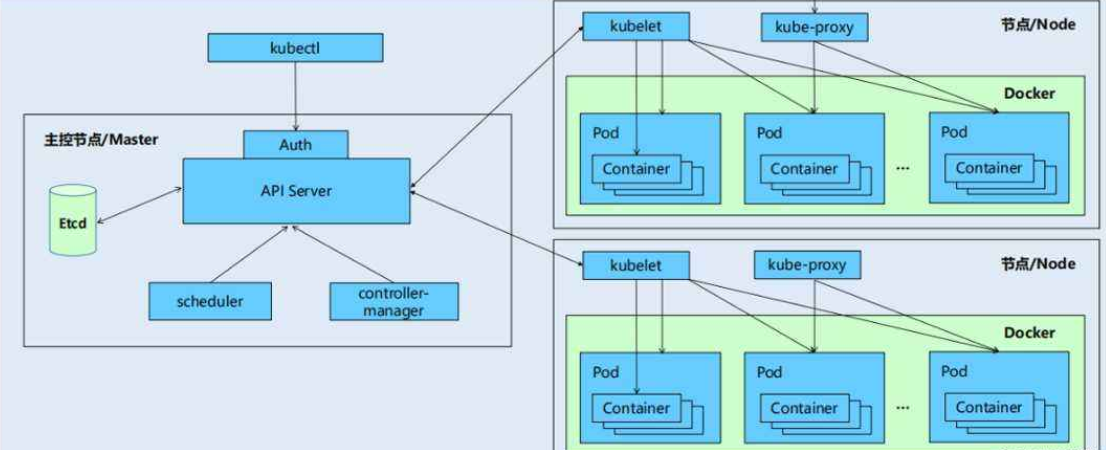
K8S核心组件之kube-proxy
kube-proxy是Kubernetes的核心组件,部署在每个Node节点上,它是实现Kubernetes Service的通信与负载均衡机制的重要组件; kube-proxy负责为Pod创建代理服务,从apiserver获取所有server信息,并根据server信息创建代理服务,实现server到Pod的请求路由和转发,从而实现K8s层级的虚拟转发网络。
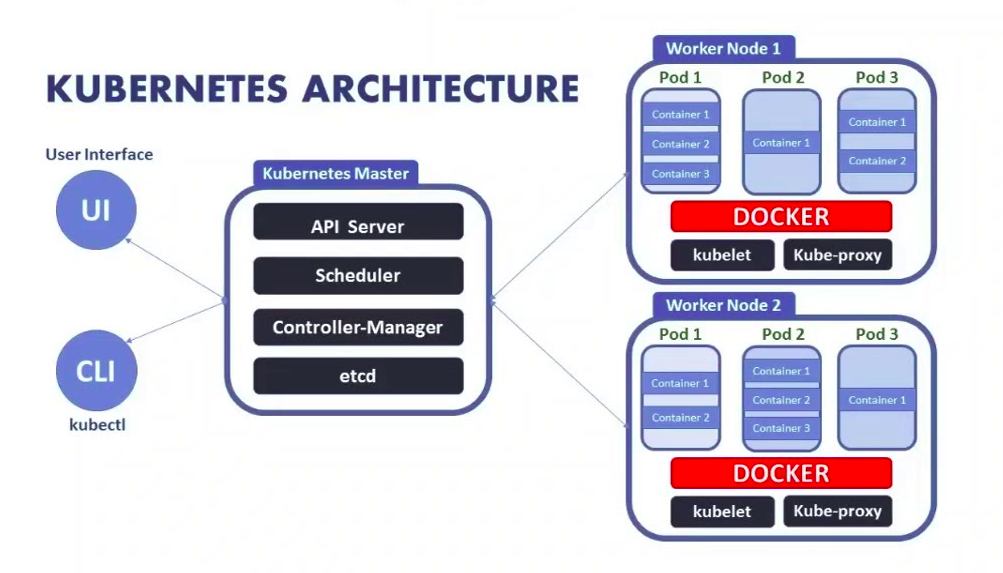
k8s架构解析
k8s有etcd、apiserver、controller manager、scheduler、kubelet、Container runtime、kube-proxy等核心组件
Kubernetes 的核心技术概念和 API 对象
API 对象是 Kubernetes 集群中的管理操作单元。Kubernetes 集群系统每支持一项新功能,引入一项新技术,一定会新引入对应的 API 对象,支持对该功能的管理操作。例如副本集 Replica Set 对应的 API 对象是 RS......
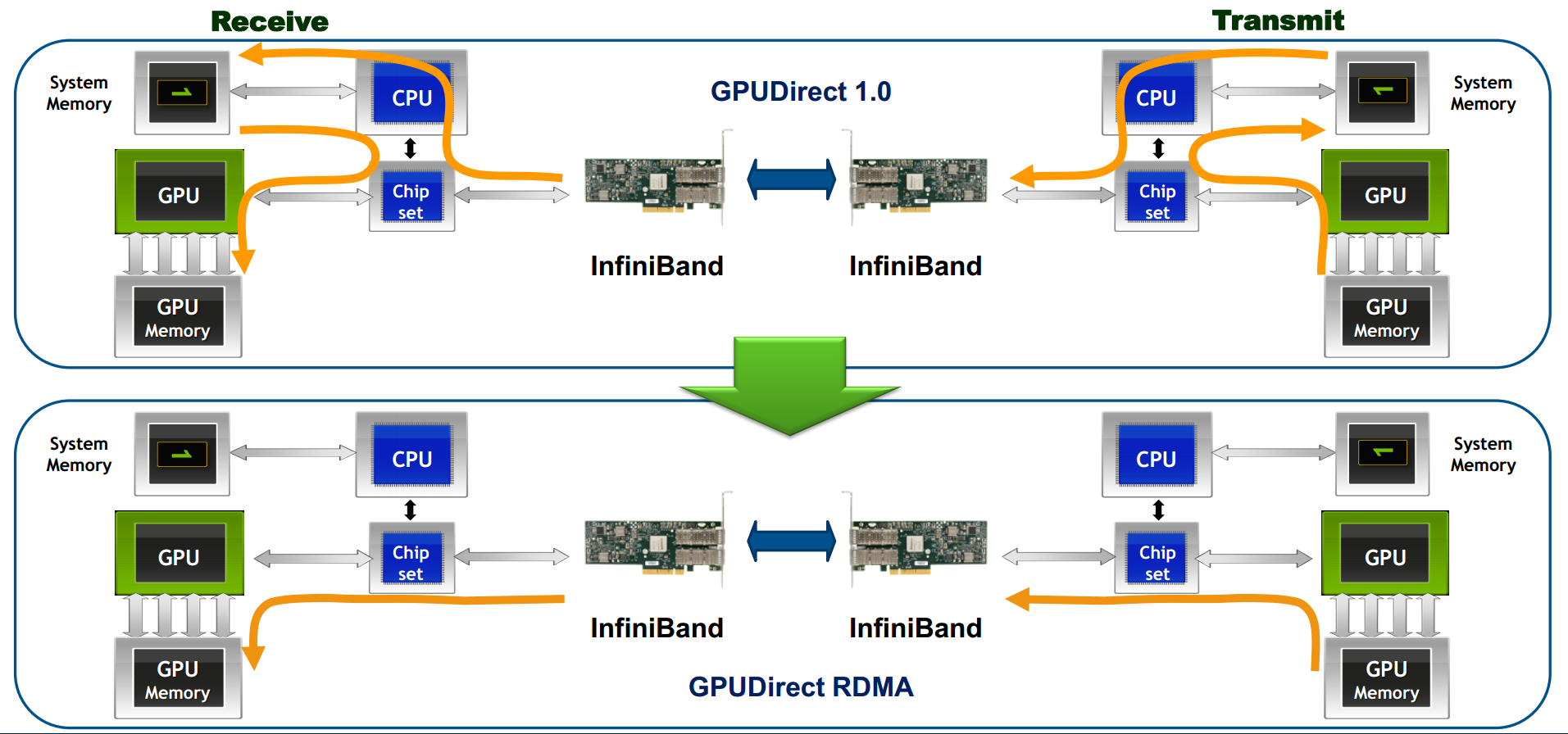
浅析GPU通信技术(下)-GPUDirect RDMA
目录 浅析GPU通信技术(上)-GPUDirect P2P 浅析GPU通信技术(中)-NVLink 浅析GPU通信技术(下)-GPUDirect RDMA 1. 背景 前两篇文章我们介绍的GPUDirect P2P和NVLink技术可以大大提升GPU服务器单机的GPU通信性...
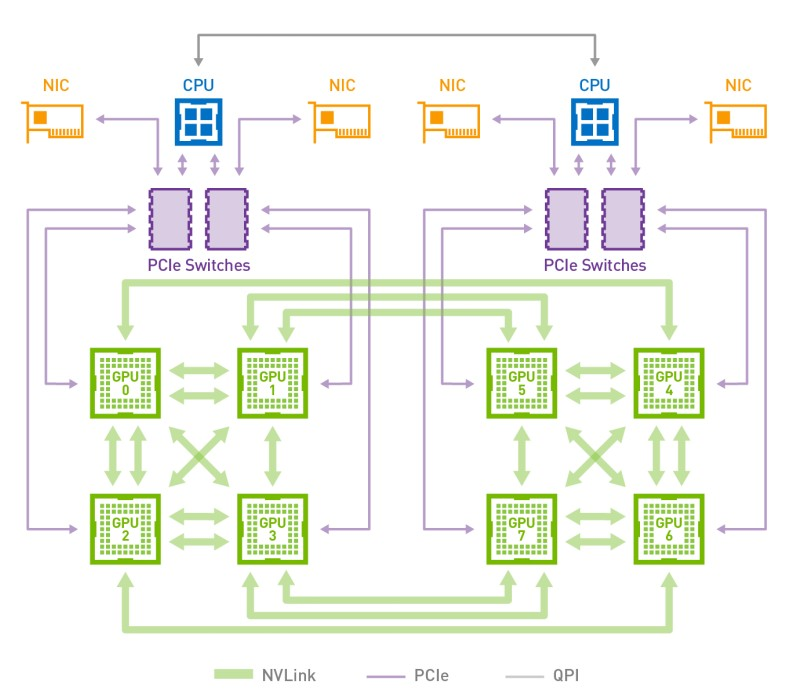
浅析GPU通信技术(中)-NVLink
背景 上一篇文章《浅析GPU通信技术(上)-GPUDirect P2P》中我们提到通过GPUDirect P2P技术可以大大提升GPU服务器单机的GPU通信性能,但是受限于PCI Expresss总线协议以及拓扑结构的一些限制,无法做到更高的带宽,为了解决这个问题,NVIDIA提出了NVLink总线协议。
上一页
1
2
3
4
5
6
7
8
下一页
qingshanyinyin
太阳底下没有阴影
河南 - 郑州
分类导航
Golang
PHP
MySQL
Nginx
Linux
Java
Javascript
HTML
CSS
JSON
Laravel
Yii
ThinkPHP
Beego
Redis
Web
K8S
A100
Docker
AI
CPU
GPU
IoT
GPT
热文排行
linux 常用命令
A100阅读笔记
一个nvidia-docker引发k8s崩溃的问题探讨
浅析GPU通信技术(中)-NVLink
Kubernetes 的核心技术概念和 API 对象
Linux绑定CPU运行指定进程(绑核)-taskset
Docker存储驱动之--overlay2
k8s架构解析
关于我们
浅析GPU通信技术(下)-GPUDirect RDMA
友情链接
Binger
Davidstack
Layui
GitHub
Yspace
Beego
Yii2
Laravel
Binger
网站首页
文章专栏
资源分享
点点滴滴
关于本站