网站首页 文章专栏 浅析GPU通信技术(中)-NVLink
参考:阿里云社区,https://developer.aliyun.com/article/591403;如侵权,请联系删除!
简介: 1. 背景 GPU在高性能计算和深度学习加速中扮演着非常重要的角色, GPU的强大的并行计算能力,大大提升了运算性能。随着运算数据量的不断攀升,GPU间需要大量的交换数据,GPU通信性能成为了非常重要的指标。
1. 背景
上一篇文章《浅析GPU通信技术(上)-GPUDirect P2P》中我们提到通过GPUDirect P2P技术可以大大提升GPU服务器单机的GPU通信性能,但是受限于PCI Expresss总线协议以及拓扑结构的一些限制,无法做到更高的带宽,为了解决这个问题,NVIDIA提出了NVLink总线协议。
本篇文章我们就来谈谈NVIDIA提出的NVLink总线协议,看看它到底是何方神圣。
2. NVlink介绍
2.1 发布
NVLink技术是在2014年3月的NVIDIA GTC 2014上发布的。对普通消费者来说,这一届的GTC似乎没有太多的亮点,也没有什么革命性的产品发布。这次GTC上,黄仁勋展示了新一代单卡双芯卡皇GeForce Titan Z,下一代GPU架构Pascal也只是初露峥嵘。在黄仁勋演讲中只用大约五六页PPT介绍的NVLink也很容易被普通消费者忽视,但是有心的专业人士确从此举看到了NVIDIA背后巨大的野心。
首先我们简单看下NVIDIA对NVLink的介绍:NVLink能在多GPU之间和GPU与CPU之间实现非凡的连接带宽。带宽有多大?2016发布的P100是搭载NVLink的第一款产品,单个GPU具有160GB/s的带宽,相当于PCIe Gen3 * 16带宽的5倍。去年GTC 2017上发布的V100搭载的NVLink 2.0更是将GPU带宽提升到了300G/s,差不多是PCIe的10倍了。
好了,这下明白了为什么NVIDIA的NVLink会如此的引人注意了。但是NVLink背后的布局远不只是如此。
2.2 解读
我们来看看NVLink出现之前的现状:
1)PCIe:
PCIe Gen3每个通道(每个Lane)的双向带宽是2B/s,GPU一般是16个Lane的PCIe连接,所以PCIe连接的GPU通信双向带宽可以达到32GB/s,要知道PCIe总线堪称PC系统中第二快的设备间总线(排名第一的是内存总线)。但是在NVLink 300GB/s的带宽面前,只有被碾压的份儿。
2)显存带宽:
上一代卡皇Geforce Titan XP的GDDR5X显存带宽已经达到547.7 GB/s,搭载HBM2显存的V100的带宽甚至达到了900GB/s。显卡核心和显存之间的数据交换通道已经达到如此高的带宽,但是GPU之间以及GPU和CPU之间的数据交换确受到PCIe总线的影响,成为了瓶颈。这当然不是NVIDIA希望看到的,而NVLink的出现,则是NVIDIA想打破这个瓶颈的宣言。
3)CPU连接:
实际上,NVLink不但可以实现GPU之间以及GPU和CPU之间的互联,还可以实现CPU之间的互联。从这一点来看,NVLink的野心着实不小。
我们知道,Intel的CPU间互联总线是QPI,20位宽的QPI连接带宽也只有25.6GB/s,在NVLink面前同样差距巨大。可想而知,如果全部采用NVLink总线互联,会对系统数据交换通道的带宽有多大提升。
当然,NVIDIA自己并没有CPU,X86仍然是当今CPU的主流架构,被Intel把持方向和趋势,NVLink绝没有可能进入X86 CPU连接总线的阵营。于是便有了NVIDIA和IBM组成的OpenPower联盟。
NVIDIA是受制于没有CPU,而IBM则恰好相反,IBM有自己的CPU,Power 处理器的性能惊艳,但IBM缺少相应的并行计算芯片,因此仅仅依靠自己的CPU,很难在目前的异构计算中发挥出优秀的性能、规模和性能功耗比优势。从这一点来看,IBM和NVIDIA互补性就非常强了,这也是IBM为什么要和NVIDIA组建OpenPower超级计算联盟的原因了。
考虑到目前POWER生态的逐渐萎缩,要想在人工智能浪潮下趁机抢占X86的市场并不是件容易的事情,但至少给了NVIDIA全面抗衡Intel的平台。
所以有点扯远了,NVLink目前更主要的还是大大提升了GPU间通信的带宽。
2.3 结构和拓扑
2.3.1 NVLink信号与协议
NVLink控制器由3层组成,即物理层(PHY)、数据链路层(DL)以及交易层(TL)。下图展示了P100 NVLink 1.0的各层和链路:
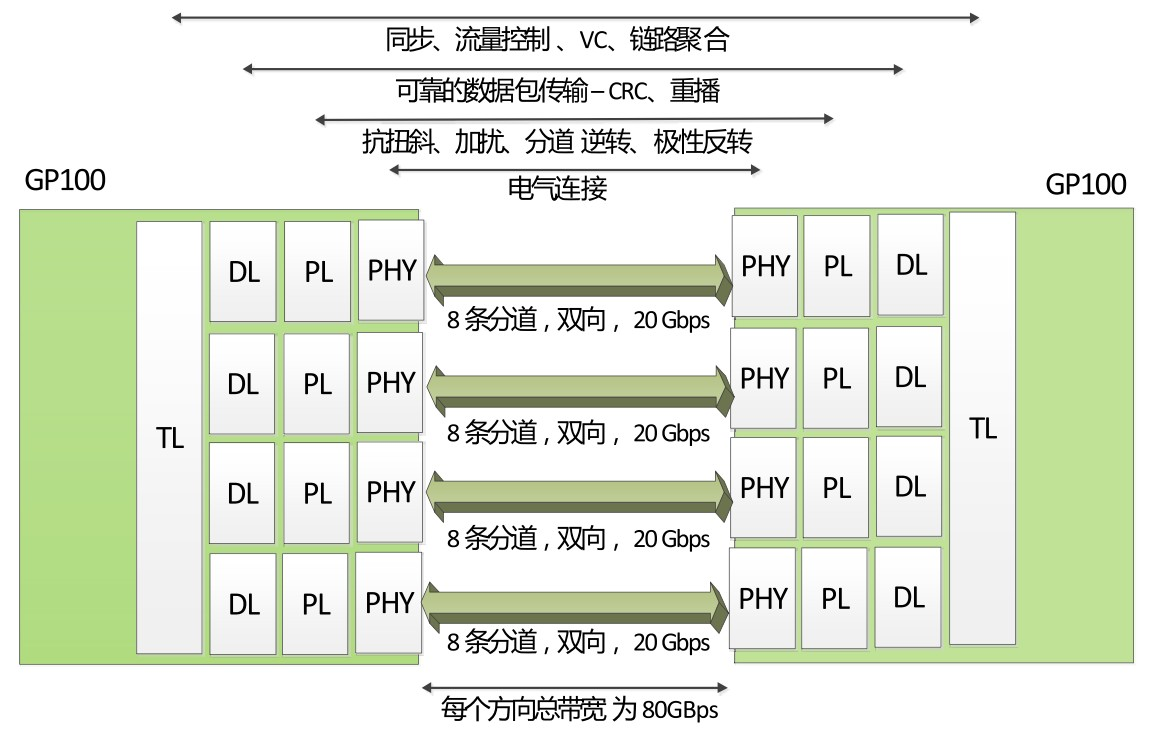
P100搭载的NVLink 1.0,每个P100有4个NVLink通道,每个拥有40GB/s的双向带宽,每个P100可以最大达到160GB/s带宽。
V100搭载的NVLink 2.0,每个V100增加了50%的NVLink通道达到6个,信号速度提升28%使得每个通道达到50G的双向带宽,因而每个V100可以最大达到300GB/s的带宽。
2.3.2 拓扑
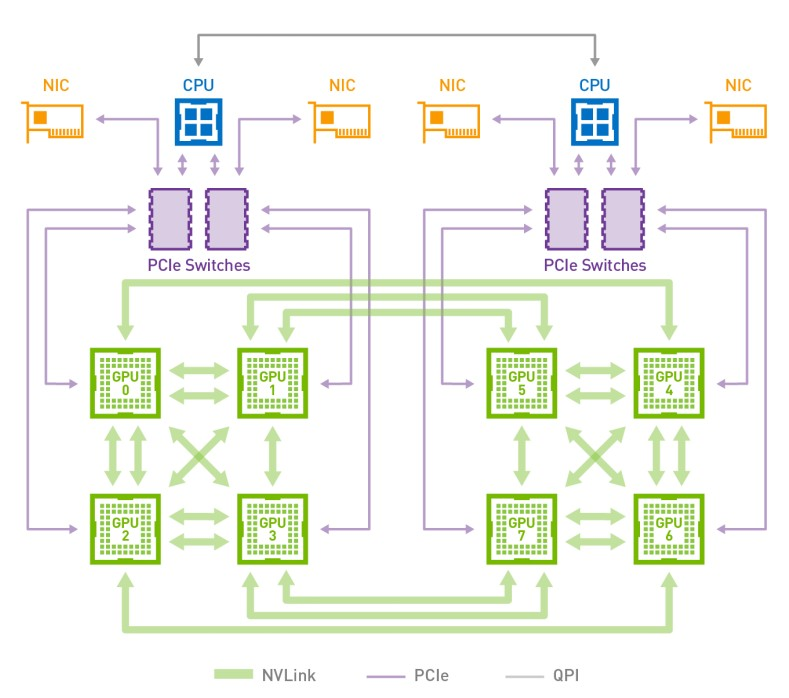
下图是HGX-1/DGX-1使用的8个V100的混合立方网格拓扑结构,我们看到虽然V100有6个NVlink通道,但是实际上因为无法做到全连接,2个GPU间最多只能有2个NVLink通道100G/s的双向带宽。而GPU与CPU间通信仍然使用PCIe总线。CPU间通信使用QPI总线。这个拓扑虽然有一定局限性,但依然大幅提升了同一CPU Node和跨CPU Node的GPU间通信带宽。
2.3.3 NVSwitch
为了解决混合立方网格拓扑结构的问题,NVIDIA在今年GTC 2018上发布了NVSwitch。
类似于PCIe使用PCIe Switch用于拓扑的扩展,NVIDIA使用NVSwitch实现了NVLink的全连接。NVSwitch作为首款节点交换架构,可支持单个服务器节点中 16 个全互联的 GPU,并可使全部 8 个 GPU 对分别以 300 GB/s 的惊人速度进行同时通信。这 16 个全互联的 GPU (32G显存V100)还可作为单个大型加速器,拥有 0.5 TB 统一显存空间和 2 PetaFLOPS 计算性能。
关于NVSwitch的相关技术细节可以参考NVIDIA官方技术文档。应该说这一技术的引入,使得GPU间通信的带宽又大大上了一个台阶。

3. NVlink与NVSwitch对比
NVIDIA® NVLink® 是一种高速、直接的 GPU 到 GPU 互联技术。NVIDIA NVSwitch™ 将多个 NVLink 加以整合,在单个节点(如 NVIDIA HGX™ A100)内以 NVLink 的较高速度实现多对多的 GPU 通信,从而进一步提高互联性能。NVLink 和 NVSwitch 的结合使 NVIDIA 得以高效地将 AI 性能扩展到多个 GPU,并在业内首个 AI 基准测试 MLPerf 0.6 中斩获佳绩。

