网站首页 文章专栏 怎样用好Kubernetes的NUMA对齐?
什么是NUMA
NUMA的全称叫Non-Uniform Memory Access,非均匀访问存储模型。第一次见到的时候,每个字都认识,但是完全不知道它在说什么。那索性就不要管字面意思,内涵意思就是在服务器上为了支持扩展多处理器而设计的一种硬件架构。现在基本市面上见到的大部分服务器都是NUMA架构的,这是不是就简单了。
NUMA架构
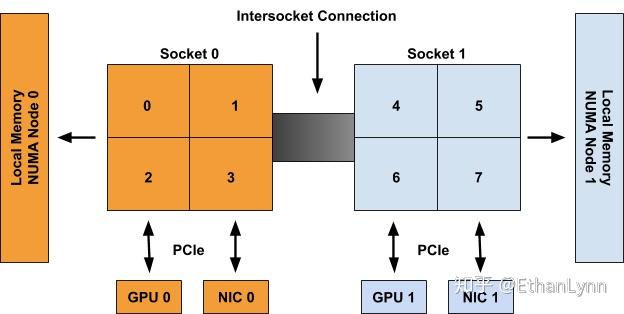
来看上面这张图感受一下NUMA架构,一个Socket就是一个CPU处理器。
有一部分内存条离Socket0比较近,有一部分内存条离Socket1比较近。
有一些PCIe设备离Socket0比较近,有一些PCIe设备离Socket1比较近。
既然有远近,就会有距离,既然有距离,就会产生美。啊不,产生性能损失。
相近的CPU内存和PCIe设备就组成了一个NUMA Node的概念,上图就有两个NUMA Node,分别是Node 0和Node 1。
NUMA优化
当一个程序启动时,如果CPU分到了Socket1上面,而数据加载到了Socket0的内存上(虽然这种可能性不大),那么CPU从内存加载数据的时间就会变长。
对于网卡来说也一样,如果有一个程序跑在了Socket1上面,但是需要处理NIC0的数据,就需要跨CPU搬运数据,这样的性能损失对5G应用来说可能会致命。
所以最理想的情况就是5G的应用跑在同一个NUMA Node里面,使得所有数据访问的距离和时间最短,不需要跨node搬运数据。
Kubernetes的NUMA调度机制
我们都知道k8s启动的是一个POD,里面跑了一个或者多个容器。对于5G平台来说,容器里面就是各种数据转发和控制程序,对延时和流量要求极高。
那么k8s的调度器是如何保证?
靠kubelet的组件TopologyManager。当pod创建的时候,topology manager根据配置的policy策略来调度pod,有如下几种调度策略
none(default) 什么也不干,随便调度,极容易产生Pod3的例子,CPU内存和网卡分别位于不同的NUMA Node上。
best-effort 根据当前pod的资源请求,尽量满足pod分配的资源,不满足的就随意了。
restricted 严格保证pod的资源请求,如果资源不满足pod的affinity需求,pod就会进入terminated状态。
single-numa-node policy pod的请求都会从一个单独的NUMA node分配,如果不满足,pod会进入terminated状态。这个跟前两个的区别是,前两个可以请求从两个NUMA Node都分配资源。

所以5G的高性能的场景下面,我们需要吧kubelet配置成single-numa-node policy,让k8s保证pod都在一个NUMA node上。
正确的调度就是Pod1和Pod2这样,所有的资源分配都集中在一个NUMA Node里面来实现最佳性能,Pod3就是一个低性能的例子。
Kubernetes的NUMA发现机制
既然Topology Manager可以做调度,那它的信息源来自于哪里呢,谁来告诉他Host的不同硬件的NUMA信息呢?
这时候就要依赖于Device Plugin了,k8s有各种各样的第三方硬件厂商的device plugin,包括intel CPU的,nvidia GPU的,FPGA的,SRIOV的等等,这些plugin会发现节点上的硬件并报告硬件的NUMA关系给Topology Manager。NUMA报告的接口如下:
message TopologyInfo { repeated NUMANode nodes = 1;}message NUMANode { int64 ID = 1;}在POD请求资源的时候,只需要告诉K8s需要的资源,NUMA的关系就由K8s自动帮你优化了。
spec: containers: - name: nginx image: nginx resources: limits: memory: "200Mi" cpu: "2" intel.com/sriov: "1" requests: memory: "200Mi" cpu: "2" intel.com/sriov: "1"l
最后的最后
TopologyManager在1.17版本的时候还是alpha,在1.18版本也仅仅是beta状态。
DevicePlugin的NUMA报告接口在1.17的时候才有。
所以k8s太老(3个月的k8s就是老者了)就享受不到这些优化了。