网站首页 文章专栏 手撸一个transformer、time-MOE(二)
手撸一个transformer、time-MOE(二)
编辑时间:2026-06-24 19:21:30
作者:linxi
浏览量:25
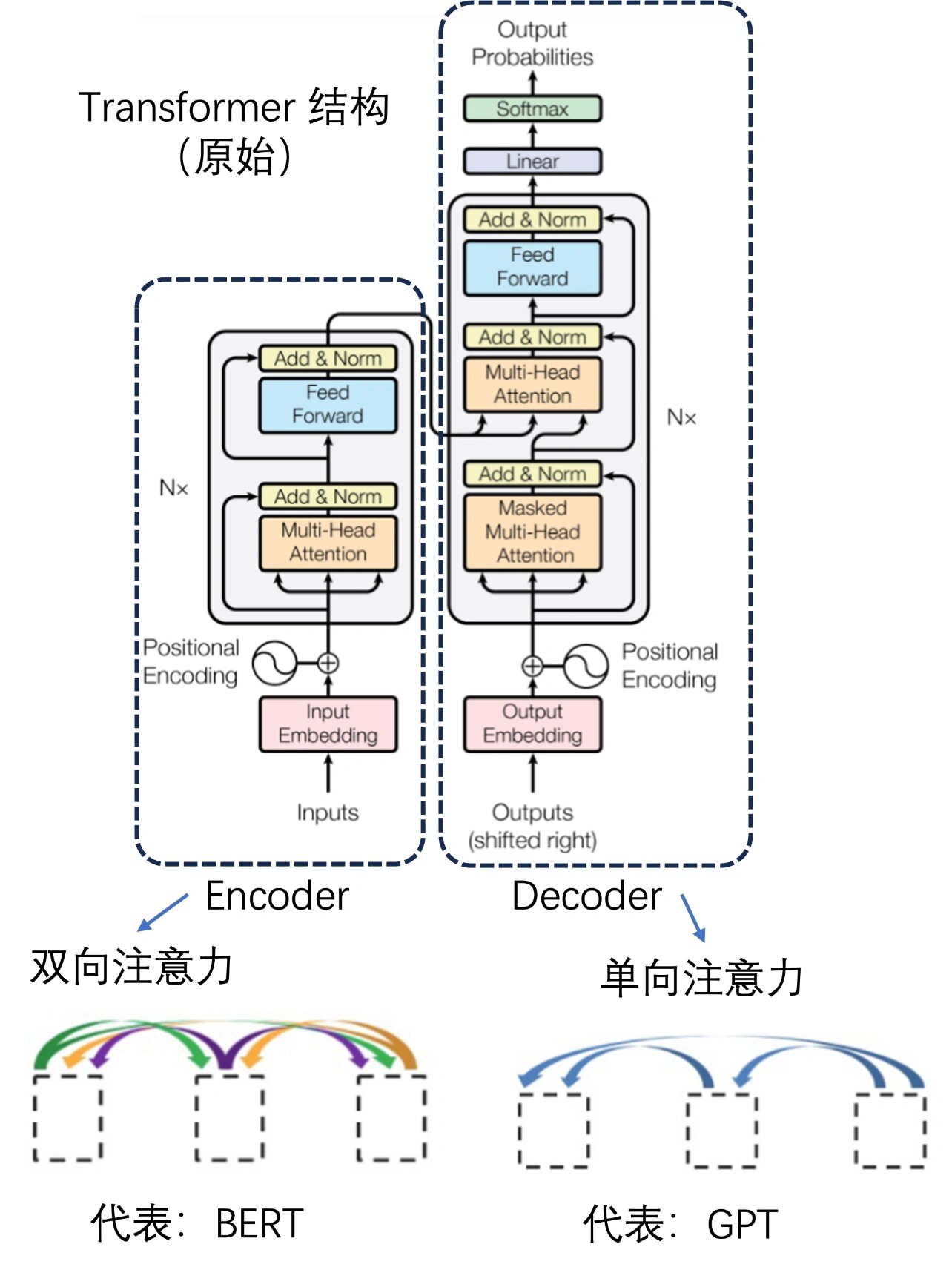
接上篇博文,详解transformer架构及示例代码
import tensorflow as tf
from keras import layers
class MultiHeadSelfAttention(layers.Layer):
"""
多头自注意力机制 (Multi-Head Self-Attention)
公式: MultiHead(Q, K, V) = Concat(head_1, ..., head_h) · W^O
其中 head_i = Attention(Q·W_i^Q, K·W_i^K, V·W_i^V)
论文默认配置 (Attention Is All You Need, 2017):
embed_dim (d_model) = 512
num_heads (h) = 8
head_dim (d_k) = 64
"""
def __init__(self, embed_dim, num_heads):
super(MultiHeadSelfAttention, self).__init__()
assert embed_dim % num_heads == 0, "嵌入维度必须能被头数整除"
self.num_heads = num_heads # 头的数量 (论文 8)
self.head_dim = embed_dim // num_heads # 每个头的维度 (论文 64)
self.embed_dim = embed_dim # 总嵌入维度 (论文 512)
# ============================================================
# 三个线性投影: 把输入 X 投影到 Q、K、V
# 输出维度都是 embed_dim, 后面再 reshape 拆多头
# (与 QKV.py 不同: 那里 dim_k 和 dim_v 可以独立; 这里统一到 embed_dim)
#
# weight 形状 (Dense 层 kernel 形状 [in, out]):
# self.wq.kernel: [embed_dim, embed_dim] = [512, 512]
# self.wk.kernel: [embed_dim, embed_dim] = [512, 512]
# self.wv.kernel: [embed_dim, embed_dim] = [512, 512]
# ============================================================
self.wq = layers.Dense(embed_dim) # Q 投影
self.wk = layers.Dense(embed_dim) # K 投影
self.wv = layers.Dense(embed_dim) # V 投影
# 最后的输出投影: 把拼接后的多头结果融合
self.dense = layers.Dense(embed_dim)
def call(self, inputs):
"""
前向传播 (5 步流程)
--------------------
输入:
inputs: (batch_size, seq_len, embed_dim) e.g. (2, 10, 512)
输出:
output: (batch_size, seq_len, embed_dim) e.g. (2, 10, 512)
"""
# 动态取 batch_size (因为 batch 维在 TF 里常常是 None)
batch_size = tf.shape(inputs)[0] # e.g. 2
# ============================================================
# 步骤 1: 线性投影, 计算 Q、K、V
# ============================================================
# 底层计算公式 (跟 nn.Linear 一样, 都是 y = x @ W + b):
# Q = inputs @ self.wq.kernel + self.wq.bias
# K = inputs @ self.wk.kernel + self.wk.bias
# V = inputs @ self.wv.kernel + self.wv.bias
#
# 形状变化 (Keras Dense 的 kernel 形状是 [in, out], 跟 PyTorch 的 [out, in] 相反):
# inputs: [B, L, D] = [2, 10, 512]
# self.wq.kernel:[D, D] = [512, 512]
# self.wq.bias: [D] = [512]
#
# 矩阵乘过程 (最后两维做线性变换, 前面的 B, L 自动遍历):
# inputs @ self.wq.kernel
# = [2, 10, 512] @ [512, 512] (内圈 512 配对 ✓)
# = [2, 10, 512]
# + self.wq.bias (广播加到最后一维)
# = [2, 10, 512]
#
# 形状: inputs[B, L, D] → Q[B, L, D] (D = embed_dim = 512)
q = self.wq(inputs) # (2, 10, 512) = [2, 10, 512] @ [512, 512] + [512]
k = self.wk(inputs) # (2, 10, 512) = [2, 10, 512] @ [512, 512] + [512]
v = self.wv(inputs) # (2, 10, 512) = [2, 10, 512] @ [512, 512] + [512]
# ============================================================
# 步骤 2: 拆分多头 (reshape)
# ============================================================
# 把最后一维 embed_dim 拆成 (num_heads, head_dim)
# 形状变化:
# [B, L, embed_dim]
# = [B, L, num_heads * head_dim]
# → [B, L, num_heads, head_dim]
# e.g. [2, 10, 512] → [2, 10, 8, 64]
# 含义: 把 512 维的 token 切成 8 个 64 维的"子 token"
q = tf.reshape(q, (batch_size, -1, self.num_heads, self.head_dim)) # (2, 10, 8, 64)
k = tf.reshape(k, (batch_size, -1, self.num_heads, self.head_dim)) # (2, 10, 8, 64)
v = tf.reshape(v, (batch_size, -1, self.num_heads, self.head_dim)) # (2, 10, 8, 64)
# ============================================================
# 步骤 3: 调整维度顺序 (transpose)
# ============================================================
# 把 num_heads 维提到 seq 前面, 变成标准的 4D 注意力输入
# perm=[0, 2, 1, 3] 含义:
# 新轴0 <- 原轴0 (batch)
# 新轴1 <- 原轴2 (num_heads) ← 关键: 把头维提到前面
# 新轴2 <- 原轴1 (seq)
# 新轴3 <- 原轴3 (head_dim)
# 形状变化: [2, 10, 8, 64] → [2, 8, 10, 64]
# 现在每个头有自己的 (seq, head_dim) = (10, 64) 矩阵
q = tf.transpose(q, perm=[0, 2, 1, 3]) # (2, 8, 10, 64)
k = tf.transpose(k, perm=[0, 2, 1, 3]) # (2, 8, 10, 64)
v = tf.transpose(v, perm=[0, 2, 1, 3]) # (2, 8, 10, 64)
# ============================================================
# 步骤 4: 4D 矩阵乘, 算多头自注意力(基本:缩放点积注意力机制)
# ============================================================
# transpose_b=True 等价于 k 的后两维转置
# k 转置后: [2, 8, 64, 10]
# Q · K^T: [2, 8, 10, 64] @ [2, 8, 64, 10] = [2, 8, 10, 10]
# 4D 矩阵乘规则: 前两维 (B, H) 配对当 batch, 后两维做 2D 矩阵乘
# 除以 sqrt(head_dim) 缩放 (论文用 sqrt(64) = 8)
scores = tf.matmul(q, k, transpose_b=True) / tf.math.sqrt(tf.cast(self.head_dim, tf.float32))
# scores: (2, 8, 10, 10) 8 头各一个 10×10 注意力分数矩阵
# ============================================================
# 步骤 5: Softmax + 加权求和
# ============================================================
# axis=-1 = 最后一维 (key 维)
# 对 4D 张量 [B, H, L, L], 最后一维是 L (key 维)
# 效果: 每个头的每行 (每个 query 跨所有 key) 归一化
attention_weights = tf.nn.softmax(scores, axis=-1)
# attention_weights: (2, 8, 10, 10) 每行 sum=1
# 加权求和: 把权重乘到 V 上
# attention_weights [2, 8, 10, 10] @ v [2, 8, 10, 64] = [2, 8, 10, 64]
output = tf.matmul(attention_weights, v)
# output: (2, 8, 10, 64) 8 头各一个 10×64 输出
# ============================================================
# 步骤 6: 合并多头 (transpose + reshape)
# ============================================================
# transpose 把 num_heads 维换回去
# [2, 8, 10, 64] → [2, 10, 8, 64]
# 含义: 把 8 头 64 维的"子 token"重新组织成 10 个 token, 每个 8×64=512 维
output = tf.transpose(output, perm=[0, 2, 1, 3]) # (2, 10, 8, 64)
# reshape 把 num_heads 和 head_dim 拼成 embed_dim
# [2, 10, 8, 64] → [2, 10, 512] (8*64=512=embed_dim)
output = tf.reshape(output, (batch_size, -1, self.embed_dim)) # (2, 10, 512)
# ============================================================
# 步骤 7: 输出投影 (融合多头信息:头之间的信息对结果影响,避免顺序切分、间隔切分等带来的信息丢失)
# ============================================================
# 切法 A + Dense_A: y = W_A^O · Concat_A(head_1, ..., head_8)
# 切法 B + Dense_B: y = W_B^O · Concat_B(head_1, ..., head_8)
# 如果 W_B^O = W_A^O · P, 其中 P 是 "切法 A → 切法 B" 的排列矩阵
# 那么两个 y 完全一样
# 把 8 头 64 维的拼接结果 [2, 10, 512] 用 W^O 线性变换,
# 让 8 个头的信息互相融合 (不是简单拼接)
#
# 形状变化:
# output: [2, 10, 512]
# self.dense.kernel:[512, 512]
# self.dense.bias: [512]
#
# output @ self.dense.kernel
# = [2, 10, 512] @ [512, 512]
# = [2, 10, 512]
# + self.dense.bias
# = [2, 10, 512]
#
# 形状不变, 但 8 个头之间的信息可以"混合"了
return self.dense(output) # (2, 10, 512) = [2, 10, 512] @ [512, 512] + [512]
class FeedForwardNetwork(layers.Layer):
"""
前馈神经网络 (Feed Forward Network)
结构: Dense(ffn_dim, ReLU) → Dense(embed_dim)
论文配比: ffn_dim = 4 × embed_dim
embed_dim = 512 → ffn_dim = 2048
"""
def __init__(self, embed_dim, ffn_dim):
super(FeedForwardNetwork, self).__init__()
# 第一层: 升维 + ReLU 激活, 引入非线性
# 输入 [B, L, embed_dim] → 输出 [B, L, ffn_dim]
self.fc1 = layers.Dense(ffn_dim, activation="relu") # e.g. 512 → 2048
# 第二层: 降回原维度
# 输入 [B, L, ffn_dim] → 输出 [B, L, embed_dim]
self.fc2 = layers.Dense(embed_dim) # e.g. 2048 → 512
def call(self, inputs):
"""
前向传播
输入: (B, L, embed_dim) e.g. (2, 10, 512)
输出: (B, L, embed_dim) e.g. (2, 10, 512)
"""
# 1. 升维 (512 → 2048)
# 2. 加非线性 (ReLU)
# 3. 特征混合 (dense 矩阵混 512 个特征)
# ============================================================
# 第 1 层 Dense: 升维 + ReLU
# ============================================================
# 形状变化:
# inputs: [2, 10, 512]
# self.fc1.kernel:[512, 2048] (Keras: [in, out])
# self.fc1.bias: [2048]
#
# inputs @ self.fc1.kernel
# = [2, 10, 512] @ [512, 2048]
# = [2, 10, 2048]
# + self.fc1.bias (广播)
# = [2, 10, 2048]
# 再过 ReLU (max(0, x))
# = [2, 10, 2048]
x = self.fc1(inputs) # (2, 10, 2048) = [2, 10, 512] @ [512, 2048] + [2048], ReLU
# ============================================================
# 第 2 层 Dense: 降回原维度
# ============================================================
# 形状变化:
# x: [2, 10, 2048]
# self.fc2.kernel: [2048, 512]
# self.fc2.bias: [512]
#
# x @ self.fc2.kernel
# = [2, 10, 2048] @ [2048, 512]
# = [2, 10, 512]
# + self.fc2.bias (广播)
# = [2, 10, 512]
return self.fc2(x) # (2, 10, 512) = [2, 10, 2048] @ [2048, 512] + [512]
class TransformerEncoderLayer(layers.Layer):
"""
Transformer 编码器层 (Post-LN 结构)
-----------------------------------------
包含两个子层, 每个子层都做: Sublayer → Dropout → Add → LayerNorm
论文默认参数:
embed_dim = 512, num_heads = 8, ffn_dim = 2048, dropout = 0.1
流程:
x ─┐
├→ [Multi-Head Self-Attention] → Dropout → Add → LayerNorm ─┐
│ ├→ [FFN] → Dropout → Add → LayerNorm → out
x ─┘ │
│
(x 残差回来) (out1 残差回来) │
"""
def __init__(self, embed_dim, num_heads, ffn_dim, dropout_rate=0.1):
super(TransformerEncoderLayer, self).__init__()
# ===== 子层 1: 多头自注意力 =====
self.self_attention = MultiHeadSelfAttention(embed_dim, num_heads)
self.norm1 = layers.LayerNormalization(epsilon=1e-6) # 注意力后的 LayerNorm
self.dropout1 = layers.Dropout(dropout_rate) # 注意力后的 Dropout
# ===== 子层 2: 前馈网络 =====
self.ffn = FeedForwardNetwork(embed_dim, ffn_dim)
self.norm2 = layers.LayerNormalization(epsilon=1e-6) # FFN 后的 LayerNorm
self.dropout2 = layers.Dropout(dropout_rate) # FFN 后的 Dropout
def call(self, inputs, training=False):
"""
前向传播 (Post-LN)
-------------------
输入: (B, L, embed_dim) e.g. (2, 10, 512)
输出: (B, L, embed_dim) e.g. (2, 10, 512)
"""
# ============================================================
# 子层 1: 多头注意力 + 残差 + LayerNorm
# ============================================================
# 1. 算多头注意力
attn_output = self.self_attention(inputs) # (2, 10, 512)
# 2. Dropout (训练时随机丢弃, 防止过拟合)
attn_output = self.dropout1(attn_output, training=training) # (2, 10, 512)
# 3. 残差连接 + LayerNorm
# inputs + attn_output: 把原始输入加回来 (梯度直通, 解决深层网络训练难)
# LayerNorm: 对每个 token 的特征做归一化,稳定训练
out1 = self.norm1(inputs + attn_output) # (2, 10, 512)
# ============================================================
# 子层 2: 前馈网络 + 残差 + LayerNorm
# ============================================================
# 1. 算 FFN
ffn_output = self.ffn(out1) # (2, 10, 512)
# 2. Dropout
ffn_output = self.dropout2(ffn_output, training=training) # (2, 10, 512)
# 3. 残差连接 + LayerNorm
return self.norm2(out1 + ffn_output) # (2, 10, 512)
class TransformerEncoder(layers.Layer):
"""
多层 Transformer 编码器 (论文 base 模型堆 6 层)
把 N 个 TransformerEncoderLayer 顺序堆叠
"""
def __init__(self, num_layers, embed_dim, num_heads, ffn_dim, dropout_rate=0.1):
super(TransformerEncoder, self).__init__()
# 顺序创建 num_layers 个 EncoderLayer
self.encoder_layers = [
TransformerEncoderLayer(embed_dim, num_heads, ffn_dim, dropout_rate)
for _ in range(num_layers)
]
def call(self, inputs, training=False):
"""
前向传播
输入: (B, L, embed_dim)
输出: (B, L, embed_dim) 形状不变
"""
# 逐层前向: 第1层输出 → 第2层输入 → ... → 第N层输出
x = inputs
for layer in self.encoder_layers:
x = layer(x, training=training)
return x
# ============================================================
# 下面是 Transformer Decoder 部分
# (上面的 Encoder 4 个类一行不动, 这里是新增)
# ============================================================
class MaskedMultiHeadSelfAttention(layers.Layer):
"""
带 mask 的多头自注意力 (GPT / Decoder 风格)
跟 MultiHeadSelfAttention 几乎一样, 唯一区别:
算完分数后, 加一个下三角 mask, 让 token 只能看到自己和之前的
论文默认配置:
embed_dim = 512, num_heads = 8, head_dim = 64
"""
def __init__(self, embed_dim, num_heads):
super(MaskedMultiHeadSelfAttention, self).__init__()
assert embed_dim % num_heads == 0, "嵌入维度必须能被头数整除"
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.embed_dim = embed_dim
# 跟 MultiHeadSelfAttention 一样的 4 个 Dense
self.wq = layers.Dense(embed_dim)
self.wk = layers.Dense(embed_dim)
self.wv = layers.Dense(embed_dim)
self.dense = layers.Dense(embed_dim)
def call(self, inputs):
"""
前向传播 (跟 MultiHeadSelfAttention 几乎一样, 只多了 mask)
输入: (B, L, embed_dim) e.g. (2, 8, 512) ← Decoder 输入
输出: (B, L, embed_dim) e.g. (2, 8, 512)
"""
batch_size = tf.shape(inputs)[0] # 2
# ============================================================
# 步骤 1: 线性投影
# ============================================================
# 形状: (B, L, D) = (2, 8, 512) → (B, L, D) = (2, 8, 512) (Dense 不改维)
q = self.wq(inputs) # (2, 8, 512) = (2, 8, 512) @ (512, 512) + (512,)
k = self.wk(inputs) # (2, 8, 512)
v = self.wv(inputs) # (2, 8, 512)
# ============================================================
# 步骤 2: 拆多头
# ============================================================
# 形状: (B, L, D) = (2, 8, 512) → (B, L, H, head_dim) = (2, 8, 8, 64)
# 含义: 把 512 维切 8 头, 每头 64 维
q = tf.reshape(q, (batch_size, -1, self.num_heads, self.head_dim)) # (2, 8, 8, 64)
k = tf.reshape(k, (batch_size, -1, self.num_heads, self.head_dim)) # (2, 8, 8, 64)
v = tf.reshape(v, (batch_size, -1, self.num_heads, self.head_dim)) # (2, 8, 8, 64)
# ============================================================
# 步骤 3: transpose 调整顺序
# ============================================================
# 形状: (B, L, H, head_dim) = (2, 8, 8, 64) → (B, H, L, head_dim) = (2, 8, 8, 64)
# 含义: 把头维提到前面, 变成 4D 注意力标准输入
q = tf.transpose(q, perm=[0, 2, 1, 3]) # (2, 8, 8, 64)
k = tf.transpose(k, perm=[0, 2, 1, 3]) # (2, 8, 8, 64)
v = tf.transpose(v, perm=[0, 2, 1, 3]) # (2, 8, 8, 64)
# ============================================================
# 步骤 4: 算注意力分数 (跟 MultiHeadSelfAttention 一样)
# ============================================================
# 形状: Q·K^T: (B, H, L, head_dim) @ (B, H, head_dim, L)
# = (B, H, L, L) = (2, 8, 8, 8)
# 除以 sqrt(head_dim)=sqrt(64)=8 缩放
scores = tf.matmul(q, k, transpose_b=True) / tf.math.sqrt(tf.cast(self.head_dim, tf.float32))
# scores: (2, 8, 8, 8) 8 头各一个 8×8 注意力分数矩阵
# ============================================================
# 步骤 5: ★ 加 mask ★ (这是 Masked 版本的核心)
# ============================================================
# 训练时如果让 Decoder "看到未来",就 作弊 了!推理时,自回归也会出现这个问题
# mask 是一个下三角矩阵, 主对角线及以下为 1, 以上为 0
# e.g. (L=8 时, 但示意用 L=4 画):
# [[1, 0, 0, 0], 词1 只能看自己
# [1, 1, 0, 0], 词2 看 词1+自己
# [1, 1, 1, 0], 词3 看 词1, 词2 + 自己
# [1, 1, 1, 1]] 词4 看全部
#
# 把"看不到"的位置设成 -inf, softmax 后变 0 (即"不关注")
seq_len = tf.shape(inputs)[1] # 8
# tf.linalg.band_part(matrix, -1, 0) 取下三角 (含主对角线)
# 形状: (L, L) = (8, 8), 下三角为 1, 上三角为 0
mask = tf.linalg.band_part(tf.ones((seq_len, seq_len)), -1, 0)
# mask 形状 (8, 8), 下三角为 1, 上三角为 0
# 在 batch 和 head 维上广播 mask
# 形状: (L, L) = (8, 8) → (1, 1, L, L) = (1, 1, 8, 8) → 自动广播到 (B, H, L, L) = (2, 8, 8, 8)
mask = tf.cast(mask, dtype=scores.dtype)
# masked_fill: mask==0 的位置填 -1e9 (近似 -inf, 数值稳定)
# 形状不变: (B, H, L, L) = (2, 8, 8, 8)
scores = scores + (1.0 - mask) * -1e9
# ============================================================
# 步骤 6: softmax + 加权
# softmax(x_i) = e^(x_i) / (e^(x_1) + e^(x_2) + ... + e^(x_n))
# 上面的 -inf 就是为了让归一化后的值为 0(趋近于0)
# ============================================================
# 形状: softmax 沿 axis=-1, 形状不变 (B, H, L, L) = (2, 8, 8, 8)
attention_weights = tf.nn.softmax(scores, axis=-1)
# 加权: (B, H, L, L) @ (B, H, L, head_dim) = (B, H, L, head_dim) = (2, 8, 8, 64)
output = tf.matmul(attention_weights, v)
# output: (2, 8, 8, 64) 8 头各一个 8×64 输出
# ============================================================
# 步骤 7: 合并多头
# ============================================================
# transpose: (B, H, L, head_dim) = (2, 8, 8, 64) → (B, L, H, head_dim) = (2, 8, 8, 64)
output = tf.transpose(output, perm=[0, 2, 1, 3]) # (2, 8, 8, 64)
# reshape: (B, L, H, head_dim) = (2, 8, 8, 64) → (B, L, D) = (2, 8, 512) (8*64=512)
output = tf.reshape(output, (batch_size, -1, self.embed_dim)) # (2, 8, 512)
# ============================================================
# 步骤 8: 输出投影
# ============================================================
# 最后的 dense: (B, L, D) = (2, 8, 512) → (B, L, D) = (2, 8, 512)
return self.dense(output) # (2, 8, 512)
class MultiHeadCrossAttention(layers.Layer):
"""
多头交叉注意力 (Cross-Attention)
跟 MultiHeadSelfAttention 几乎一样, 唯一区别:
Q 来自 Decoder 输入
K, V 来自 Encoder 输出 (不是 Decoder 自身)
"""
def __init__(self, embed_dim, num_heads):
super(MultiHeadCrossAttention, self).__init__()
assert embed_dim % num_heads == 0, "嵌入维度必须能被头数整除"
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.embed_dim = embed_dim
# 跟 Self-Attention 一样的 4 个 Dense
self.wq = layers.Dense(embed_dim) # 投影 Decoder 的 Q
self.wk = layers.Dense(embed_dim) # 投影 Encoder 的 K
self.wv = layers.Dense(embed_dim) # 投影 Encoder 的 V
self.dense = layers.Dense(embed_dim)
def call(self, x, encoder_output):
"""
前向传播
x: Decoder 上一层的输出, (B, L_dec, D) e.g. (2, 8, 512)
encoder_output: Encoder 最终的输出, (B, L_enc, D) e.g. (2, 10, 512)
返回: (B, L_dec, D) = (2, 8, 512)
"""
batch_size = tf.shape(x)[0] # 2
# ============================================================
# 步骤 1: 投影 Q, K, V
# ============================================================
# Q 用 x (Decoder 输入), K/V 用 encoder_output
# 关键: Q 的 seq_len=L_dec=8, K/V 的 seq_len=L_enc=10, 长度不一样!
# 这里交叉注意力,要用 decoder 的 Q (输入 x: I love ? very much ....) 查询 K V (encoder的输出 [2, 10, 512], 对应中文关系)
# 不是和英文做自注意力,所以叫交叉注意力:因为训练时候做了关联,所以中英文有相关性
q = self.wq(x) # (2, 8, 512) = (2, 8, 512) @ (512, 512) + (512,)
k = self.wk(encoder_output) # (2, 10, 512) = (2, 10, 512) @ (512, 512) + (512,)
v = self.wv(encoder_output) # (2, 10, 512)
# ============================================================
# 步骤 2: 拆多头
# ============================================================
# 注意: q 的 seq_len=8, k/v 的 seq_len=10
# 形状: Q (2, 8, 512) → (2, 8, 8, 64)
# K (2, 10, 512) → (2, 10, 8, 64)
# V (2, 10, 512) → (2, 10, 8, 64)
q = tf.reshape(q, (batch_size, -1, self.num_heads, self.head_dim)) # (2, 8, 8, 64)
k = tf.reshape(k, (batch_size, -1, self.num_heads, self.head_dim)) # (2, 10, 8, 64)
v = tf.reshape(v, (batch_size, -1, self.num_heads, self.head_dim)) # (2, 10, 8, 64)
# ============================================================
# 步骤 3: transpose 调整顺序
# ============================================================
# 形状: Q (2, 8, 8, 64) → (2, 8, 8, 64) [B, H, L_dec, head_dim]
# K (2, 10, 8, 64) → (2, 8, 10, 64) [B, H, L_enc, head_dim]
# V (2, 10, 8, 64) → (2, 8, 10, 64) [B, H, L_enc, head_dim]
q = tf.transpose(q, perm=[0, 2, 1, 3]) # (2, 8, 8, 64)
k = tf.transpose(k, perm=[0, 2, 1, 3]) # (2, 8, 10, 64)
v = tf.transpose(v, perm=[0, 2, 1, 3]) # (2, 8, 10, 64)
# ============================================================
# 步骤 4: 算注意力分数
# ============================================================
# 关键: Q 的 L_dec=8 ≠ K 的 L_enc=10
# 形状: Q·K^T: (B, H, L_dec, head_dim) @ (B, H, head_dim, L_enc)
# = (B, H, L_dec, L_enc) = (2, 8, 8, 10)
# 除以 sqrt(head_dim)=sqrt(64)=8 缩放
scores = tf.matmul(q, k, transpose_b=True) / tf.math.sqrt(tf.cast(self.head_dim, tf.float32))
# scores: (2, 8, 8, 10) 8 头各一个 8×10 注意力分数矩阵
# 含义: scores[b, h, i, j] = "第 b 句, 头 h, decoder 第 i 个词"
# 对 "encoder 第 j 个词" 的相关度
# ============================================================
# 步骤 5: softmax + 加权 V
# ============================================================
# 形状: softmax 沿 axis=-1, 形状不变 (B, H, L_dec, L_enc) = (2, 8, 8, 10)
# 最后一维 (L_enc=10) sum=1
attention_weights = tf.nn.softmax(scores, axis=-1)
# attention_weights: (2, 8, 8, 10) 最后一维 sum=1
# 加权: (B, H, L_dec, L_enc) @ (B, H, L_enc, head_dim) = (B, H, L_dec, head_dim)
# = (2, 8, 8, 10) @ (2, 8, 10, 64) = (2, 8, 8, 64)
output = tf.matmul(attention_weights, v)
# output: (2, 8, 8, 64) 8 头各一个 8×64 输出
# ============================================================
# 步骤 6: 合并多头
# ============================================================
# transpose: (B, H, L_dec, head_dim) = (2, 8, 8, 64) → (B, L_dec, H, head_dim) = (2, 8, 8, 64)
output = tf.transpose(output, perm=[0, 2, 1, 3]) # (2, 8, 8, 64)
# reshape: (B, L_dec, H, head_dim) = (2, 8, 8, 64) → (B, L_dec, D) = (2, 8, 512) (8*64=512)
output = tf.reshape(output, (batch_size, -1, self.embed_dim)) # (2, 8, 512)
# ============================================================
# 步骤 7: 输出投影
# ============================================================
# 最后的 dense: (B, L_dec, D) = (2, 8, 512) → (B, L_dec, D) = (2, 8, 512)
return self.dense(output) # (2, 8, 512)
class TransformerDecoderLayer(layers.Layer):
"""
Transformer 解码器层 (3 个子层, Post-LN)
-----------------------------------------
跟 TransformerEncoderLayer 类似的结构, 但多了一个子层 (Cross-Attention)
流程:
x ─┐
├→ [Masked Self-Attention] → Dropout → Add → LayerNorm ─┐
│ │
x ─┘ ├→ [FFN] → Dropout → Add → LayerNorm → out
│
┌── encoder_output (整个 Decoder 共享) ──┐ │
│ ↓ │
└─→ [Cross-Attention] → Dropout → Add → LayerNorm ─────────┘
"""
def __init__(self, embed_dim, num_heads, ffn_dim, dropout_rate=0.1):
super(TransformerDecoderLayer, self).__init__()
# ===== 子层 1: Masked Self-Attention =====
self.masked_self_attention = MaskedMultiHeadSelfAttention(embed_dim, num_heads)
self.norm1 = layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = layers.Dropout(dropout_rate)
# ===== 子层 2: Cross-Attention (新!) =====
self.cross_attention = MultiHeadCrossAttention(embed_dim, num_heads)
self.norm2 = layers.LayerNormalization(epsilon=1e-6)
self.dropout2 = layers.Dropout(dropout_rate)
# ===== 子层 3: FFN (复用上面的 FeedForwardNetwork) =====
self.ffn = FeedForwardNetwork(embed_dim, ffn_dim)
self.norm3 = layers.LayerNormalization(epsilon=1e-6)
self.dropout3 = layers.Dropout(dropout_rate)
def call(self, x, encoder_output, training=False):
"""
前向传播 (3 个子层, Post-LN)
----------------------------
x: Decoder 输入, (B, L_dec, D) e.g. (2, 8, 512)
encoder_output: Encoder 输出, (B, L_enc, D) e.g. (2, 10, 512)
返回: (B, L_dec, D) 形状不变
"""
# ============================================================
# 子层 1: Masked Self-Attention + 残差 + LayerNorm
# ============================================================
# Q=K=V=x, 内部加 mask (token 看不到未来)
attn_output = self.masked_self_attention(x) # (B, L_dec, D)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.norm1(x + attn_output) # 残差 + LN
# ============================================================
# 子层 2: Cross-Attention + 残差 + LayerNorm
# ============================================================
# Q=out1 (Decoder 上一子层), K/V=encoder_output
cross_output = self.cross_attention(out1, encoder_output) # (B, L_dec, D)
cross_output = self.dropout2(cross_output, training=training)
out2 = self.norm2(out1 + cross_output) # 残差 + LN
# ============================================================
# 子层 3: FFN + 残差 + LayerNorm
# ============================================================
ffn_output = self.ffn(out2) # (B, L_dec, D)
ffn_output = self.dropout3(ffn_output, training=training)
return self.norm3(out2 + ffn_output) # 残差 + LN, (B, L_dec, D)
class TransformerDecoder(layers.Layer):
"""
多层 Transformer 解码器 (论文 base 堆 6 层)
把 N 个 TransformerDecoderLayer 顺序堆叠
"""
def __init__(self, num_layers, embed_dim, num_heads, ffn_dim, dropout_rate=0.1):
super(TransformerDecoder, self).__init__()
# 顺序创建 num_layers 个 DecoderLayer
self.decoder_layers = [
TransformerDecoderLayer(embed_dim, num_heads, ffn_dim, dropout_rate)
for _ in range(num_layers)
]
def call(self, x, encoder_output, training=False):
"""
前向传播
x: Decoder 输入, (B, L_dec, D)
encoder_output: Encoder 输出 (给所有 DecoderLayer 共享), (B, L_enc, D)
返回: (B, L_dec, D)
"""
# 逐层前向: 跟 Encoder 一样, 但每层还要传 encoder_output
# x 经过 Decoder 的每一个 layer 变化的
for layer in self.decoder_layers:
x = layer(x, encoder_output, training=training)
return x
class TranslationHead(layers.Layer):
"""
Transformer 翻译任务头: Linear(D → V) + Softmax
输入: (B, L_dec, D) e.g. (2, 8, 512)
输出: (logits, probs) 都是 (B, L_dec, V) e.g. (2, 8, 30000)
"""
def __init__(self, embed_dim, vocab_size):
super(TranslationHead, self).__init__()
self.linear = layers.Dense(vocab_size) # 权重 (D, V) = (512, 30000)
def call(self, decoder_output):
# 形状: (B, L_dec, D) → (B, L_dec, V)
logits = self.linear(decoder_output) # 原始分数
probs = tf.nn.softmax(logits, axis=-1) # 概率分布
return logits, probs
# ============================================================
# 测试 Transformer Encoder + Decoder (采用论文 base 模型参数)
# ============================================================
if __name__ == "__main__":
# ============================================================
# 超参数设置 (论文 base 模型配置)
# ============================================================
# batch_size = 2 一次处理 2 条样本
# seq_len = 10 每条样本 10 个 token
# embed_dim = 512 d_model: token 向量维度
# num_heads = 8 h: 注意力头数
# head_dim = 512 / 8 = 64 d_k = d_v: 每头维度
# ffn_dim = 2048 d_ff: FFN 隐藏层 (4×embed_dim)
# num_layers = 6 N: 编码器/解码器堆叠层数
# dropout = 0.1 P_drop: 论文默认值
batch_size = 2
seq_len = 10
embed_dim = 512 # 论文 d_model
num_heads = 8 # 论文 h
ffn_dim = 2048 # 论文 d_ff
num_layers = 6 # 论文 N (base 模型)
# ============================================================
# 创建 Encoder 和 Decoder
# ============================================================
encoder = TransformerEncoder(num_layers, embed_dim, num_heads, ffn_dim)
decoder = TransformerDecoder(num_layers, embed_dim, num_heads, ffn_dim)
# ============================================================
# 造测试输入
# ============================================================
# tf.random.uniform: 在 [0, 1) 上均匀分布, 仅用于造测试数据
sample_input = tf.random.uniform((batch_size, seq_len, embed_dim))
# 形状: (2, 10, 512)
# ============================================================
# Encoder 前向传播
# ============================================================
output = encoder(sample_input)
# 形状: (2, 10, 512) 输入输出形状一致
print("=== Encoder ===")
print("输入形状: ", sample_input.shape)
print("Encoder 输出形状:", output.shape)
# ============================================================
# Encoder + Decoder 联合测试
# ============================================================
# 模拟: 中文 (Encoder) → 英文 (Decoder) 翻译场景
# encoder_seq_len = 10 (中文句长)
# decoder_seq_len = 8 (英文句长, 跟中文不一样也没关系)
encoder_seq_len = 10
decoder_seq_len = 8
encoder_input = tf.random.uniform((batch_size, encoder_seq_len, embed_dim))
decoder_input = tf.random.uniform((batch_size, decoder_seq_len, embed_dim))
# 形状: encoder (2, 10, 512), decoder (2, 8, 512)
# Encoder 跑一遍, 把输出喂给 Decoder
encoder_output = encoder(encoder_input) # (2, 10, 512)
decoder_output = decoder(decoder_input, encoder_output) # (2, 8, 512)
print("\n=== Encoder-Decoder 联合 ===")
print("Encoder 输入: ", encoder_input.shape) # (2, 10, 512)
print("Encoder 输出: ", encoder_output.shape) # (2, 10, 512)
print("Decoder 输入: ", decoder_input.shape) # (2, 8, 512)
print("Decoder 输出: ", decoder_output.shape) # (2, 8, 512)
# ============================================================
# 一句话总结 (这条不会跑)
# ============================================================
# Encoder: 输入 [B, L_enc, D] → 输出 [B, L_enc, D]
# ↓ 把 encoder_output 喂给 Decoder
# Decoder: 输入 [B, L_dec, D] + encoder_output [B, L_enc, D] → 输出 [B, L_dec, D]
#
# Decoder 内部每层:
# 1. Masked Self-Attention (B, L_dec, D) → (B, L_dec, D)
# 2. Cross-Attention (B, L_dec, D) + (B, L_enc, D) → (B, L_dec, D)
# 3. FFN (B, L_dec, D) → (B, L_dec, D)
# 循环 6 次, 输出形状始终是 (B, L_dec, D)
#
# 最终输出 = (2, 8, 512) 的张量 ,每个位置是 512 维的"抽象特征向量", 不是概率。
# 位置1: 512个数,"看了中文 + 看了英文前文之后,对位置 1 的'超浓缩理解'"。
# ============================================================
# 下面是 Transformer 的"任务头": Linear + Softmax
# ============================================================
# 第一种在 Encoder & Decoder 中用于将注意力分数 (三种) 归一化,第二个在任务头中用于将输出归一化
# 用法:
# 训练: logits, probs = head(decoder_output); loss = CrossEntropy(target, probs)
# 推理: logits, probs = head(decoder_output); predicted = tf.argmax(probs, axis=-1)
vocab_size = 30000
head = TranslationHead(embed_dim, vocab_size)
test_decoder_out = tf.random.uniform((batch_size, decoder_seq_len, embed_dim))
logits, probs = head(test_decoder_out)
predicted_ids = tf.argmax(probs, axis=-1)
print("\n=== 任务头 (Linear + Softmax) ===")
print("Decoder 输出: ", test_decoder_out.shape) # (2, 8, 512)
print("Logits 形状: ", logits.shape) # (2, 8, 30000)
print("Probs 形状: ", probs.shape) # (2, 8, 30000)
print("Probs 位置0 之和: ", tf.reduce_sum(probs[0, 0]).numpy()) # 1.0
print("预测 token id: ", predicted_ids[0].numpy()) # 一串整数
最新评论