网站首页 文章专栏 手撸一个transformer、time-MOE(一)
一、transformer处理时序数据
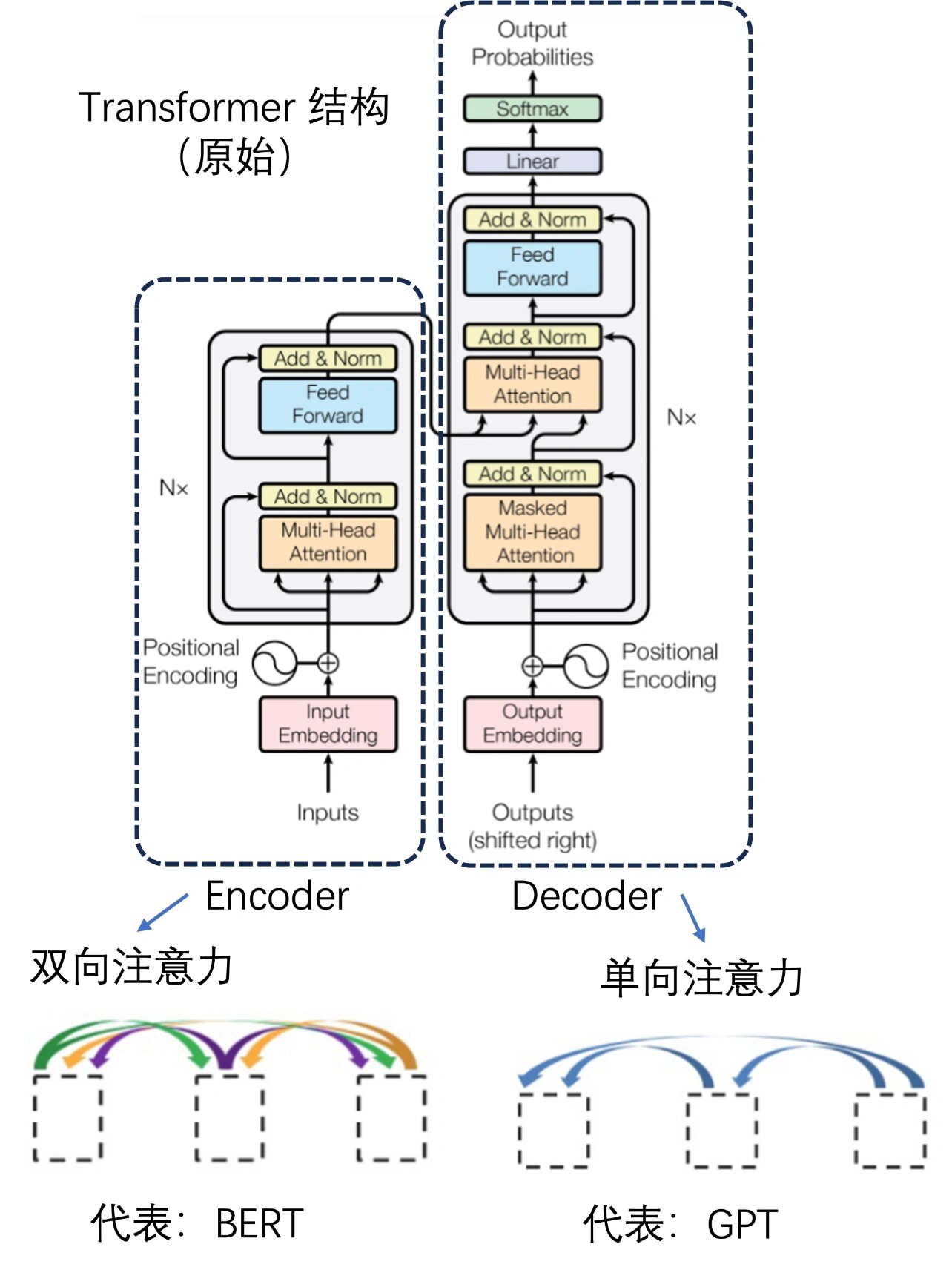
1、transformer 架构
1.1 transformer的输入
Transformer 中单词的输入表示x由 单词 Embedding 和 位置 Embedding(Positional Encoding)相加得到。
Transformer 的输入表示
1.1.1 单词 Embedding
单词的 Embedding 有很多种方式可以获取,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在Transformer 中训练得到。
1.1.2 位置 Embedding
在Transformer模型中,除词Embedding外,还需引入位置Embedding(PE)以表征单词在句子中的位置信息。
由于Transformer摒弃了RNN结构,采用全局注意力机制,无法直接获取单词的顺序信息,而这正是自然语言处理(NLP)任务中的关键要素。
因此,位置Embedding被用于编码序列中单词的相对或绝对位置关系。
位置Embedding(PE)的维度与词Embedding保持一致。
其实现方式可分为两种:通过训练学习或基于公式计算。原始Transformer论文选择了后一种方法。
计算公式如下:
其中,pos 表示单词在句子中的位置索引,d 代表位置编码(PE)的维度(与词向量维度相同),2i 对应偶数维度的编号,2i+1 对应奇数维度的编号(需满足 2i≤d 且 2i+1≤d)。
采用公式化计算位置编码(PE)的主要优势在于其动态扩展性和相对位置计算的便捷性。
当输入句子的长度超出训练集最大长度(例如训练集中最长句子为20个单词,而新句子包含21个单词时),公式可以直接计算新增位置(如第21位)的编码,无需依赖预定义的最大长度限制。
此外,对于任意固定间距 k,模型可以通过 PE(pos) 直接推导出 PE(pos+k) 的编码值,从而简化了相对位置关系的建模过程。
这种设计使得位置编码能够灵活适应不同长度的句子,并便于模型捕捉单词间的相对位置信息。
因为:Sin(A+B)= Sin(A)Cos(B)+Cos(A)Sin(B),Cos(A+B)= Cos(A)Cos(B)-Sin(A)Sin(B)。
1.2 Self-Attention(自注意力机制)
Transformer 的内部结构图
左侧为 Encoder block
右侧为 Decoder block
红色圈中的部分为 Multi-Head Attention,是由多个 Self-Attention 组成的
1)可以看到 Encoder block包含一个 Multi-Head Attention
2)而 Decoder block包含两个 Multi-Head Attention(其中有一个用到 Masked).
3)Multi-Head Attention 上方还包括一个 Add & Norm 层
4)Add 表示残差连接(Residual Connection)用于防止网络退化
5)Norm 表示Layer Normalization,用于对每一层的激活值进行归一化。
因为 Self-Attention是 Tansformer 的重点,所以我们重点关注 Mu1ti-Head Attention 以及 se1f-Attention,首先详细了解-下 self-Attention的内部逻辑。
1.2.1 Self-Attention 结构
Self-Attention 结构
上图是 se1f-Attention 的结构,在计算的时候需要用到矩阵Q(查询),K(键值),V(值)。
在实际中,Self-Attention 接收的是输入(单词的表示向量x组成的矩阵X)或者上一个 Encoder block 的输出。
而Q,K,V正是通过Self-Attention 的输入进行线性变换得到的。
1.2.2 Q,K,V 的计算
Self-Attention 的输入用矩阵X进行表示,则可以使用线性变阵矩阵WQ,WK,WV计算得到Q,K,V。
计算如下图所示,注意 X,Q,K,V的每一行都表示一个单词。
1.2.3 Self-Attention 的输出
得到矩阵 Q,K,V之后就可以计算出 Self-Attention 的输出了,计算的公式如下:
Self-Attention 的输出
Q乘以K的转置的计算
对矩阵的每一行进行 Softmax
得到 softmax 矩阵之后可以和V相乘,得到最终的输出Z。
Self-Attention输出
上图中 softmax 矩阵的第1行表示单词1 与其他所有单词的 attention 系数,最终单词1的输出 2,等于所有单词i的值 V: 根据 attention 系数的比例加在一起得到,如下图所示:
Zi 的计算方法
1.2.4 Multi-Head Attention
在前一步骤中,我们已经掌握了如何利用 Self-Attention 机制生成输出矩阵 Z。
而 Multi-Head Attention 的本质是多个 Self-Attention 的集成结构,论文中的 Multi-Head Attention 架构图如图所示。
Multi-Head Attention
Multi-Head Attention 由多个独立的 Self-Attention 层构成,其过程是将输入 X 并行分配到 h 个不同的 Self-Attention 模块中,最终输出 h 个矩阵 Z。
以 h=8 为例,此时系统会生成 8 个独立的输出矩阵 Z。
Multi-Head Attention的输出
可以看到 Multi-Head Attention输出的矩阵Z与其输入的矩阵X的维度是一样的。
1.3 Encoder 结构
红色部分展示了 Transformer 的 Encoder block 架构,其核心组件依次为 Multi-Head Attention、Add & Norm、Feed Forward 以及重复的 Add & Norm。
此前已详细解析了 Multi-Head Attention 的运算逻辑,接下来将重点探讨 Add & Norm 和 Feed Forward 的具体实现机制。
2、transformer代码
见下篇博文
3、用transformer架构预测时序数据
见下篇博文
二、time-MOE处理时序数据
见下篇博文
1、time-MOE架构
见下篇博文
2、time-MOE代码
见下篇博文
3、用time-MOE架构预测时序数据
见下篇博文