林夕-博客
网站首页
文章专栏
资源分享
点点滴滴
关于本站
网站首页
文章专栏
共有文章【
55
】篇,请查阅!
K8S核心组件之kube-proxy
kube-proxy是Kubernetes的核心组件,部署在每个Node节点上,它是实现Kubernetes Service的通信与负载均衡机制的重要组件; kube-proxy负责为Pod创建代理服务,从apiserver获取所有server信息,并根据server信息创建代理服务,实现server到Pod的请求路由和转发,从而实现K8s层级的虚拟转发网络。
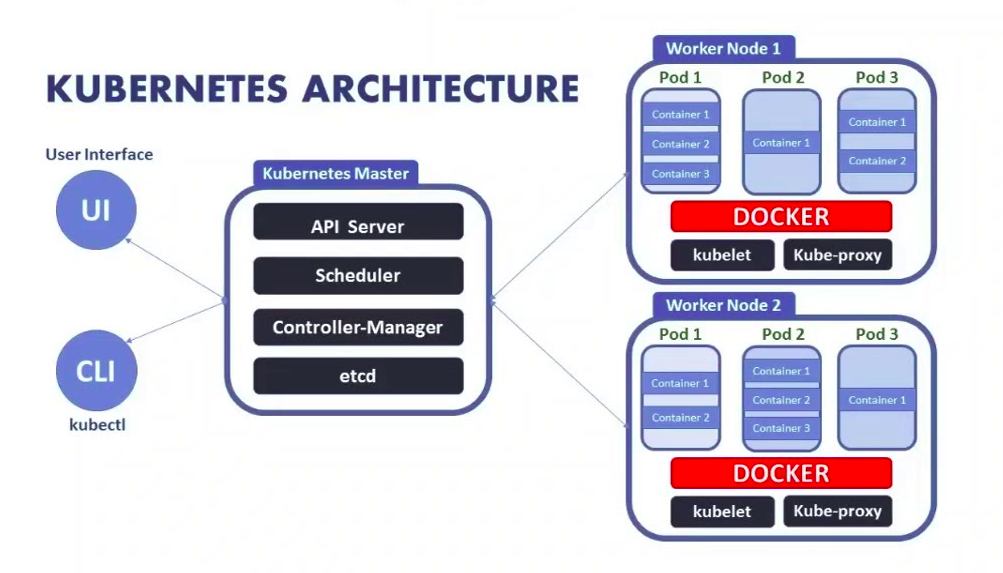
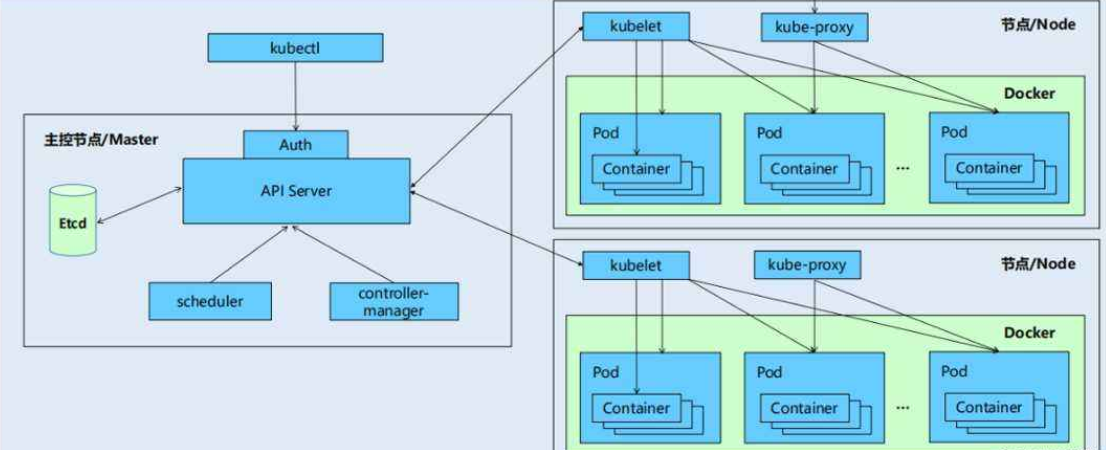
k8s架构解析
k8s有etcd、apiserver、controller manager、scheduler、kubelet、Container runtime、kube-proxy等核心组件
Kubernetes 的核心技术概念和 API 对象
API 对象是 Kubernetes 集群中的管理操作单元。Kubernetes 集群系统每支持一项新功能,引入一项新技术,一定会新引入对应的 API 对象,支持对该功能的管理操作。例如副本集 Replica Set 对应的 API 对象是 RS......
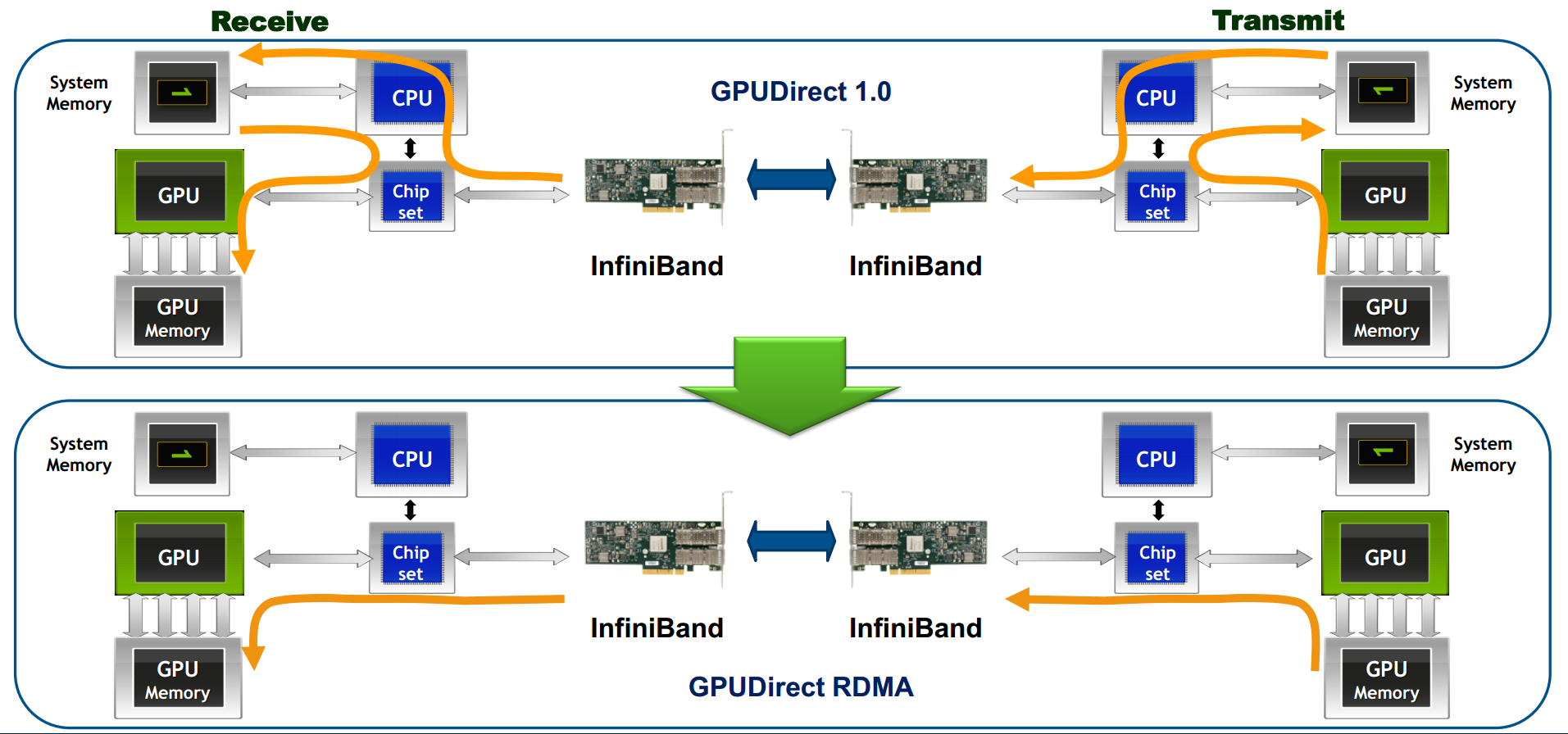
浅析GPU通信技术(下)-GPUDirect RDMA
目录 浅析GPU通信技术(上)-GPUDirect P2P 浅析GPU通信技术(中)-NVLink 浅析GPU通信技术(下)-GPUDirect RDMA 1. 背景 前两篇文章我们介绍的GPUDirect P2P和NVLink技术可以大大提升GPU服务器单机的GPU通信性...
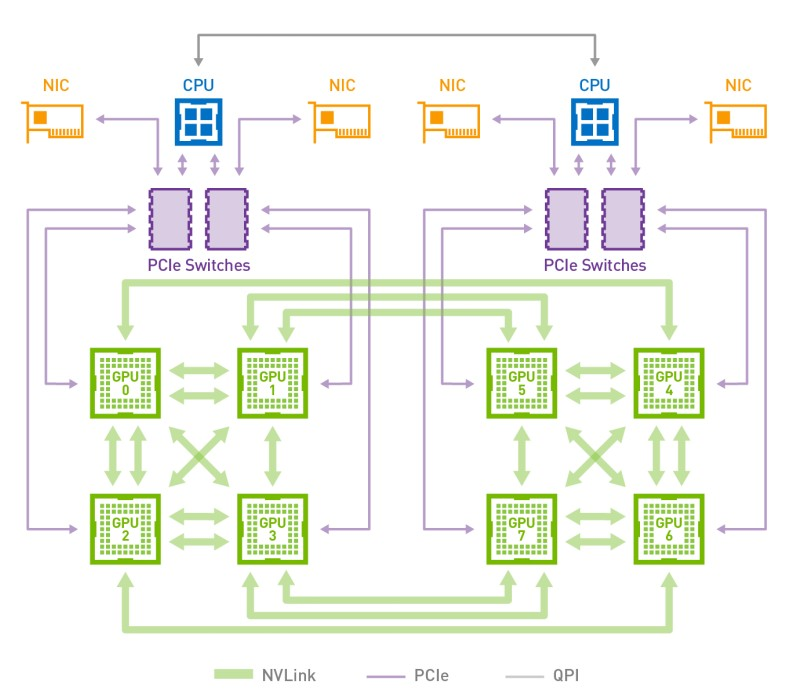
浅析GPU通信技术(中)-NVLink
背景 上一篇文章《浅析GPU通信技术(上)-GPUDirect P2P》中我们提到通过GPUDirect P2P技术可以大大提升GPU服务器单机的GPU通信性能,但是受限于PCI Expresss总线协议以及拓扑结构的一些限制,无法做到更高的带宽,为了解决这个问题,NVIDIA提出了NVLink总线协议。
上一页
1
2
3
4
5
6
7
8
9
10
11
下一页
分类导航
Golang
PHP
MySQL
Nginx
Linux
Java
Javascript
HTML
CSS
JSON
Laravel
Yii
ThinkPHP
Beego
Redis
Web
K8S
A100
Docker
AI
CPU
GPU
IoT
GPT
热门文章
linux 常用命令
A100阅读笔记
一个nvidia-docker引发k8s崩溃的问题探讨
浅析GPU通信技术(中)-NVLink
Kubernetes 的核心技术概念和 API 对象
Linux绑定CPU运行指定进程(绑核)-taskset
Docker存储驱动之--overlay2
k8s架构解析
关于我们
浅析GPU通信技术(下)-GPUDirect RDMA
网站首页
文章专栏
资源分享
点点滴滴
关于本站